Critica computazionale
Metodi e prospettive
Giornata di studi in Filologia Digitale
Dipartimento di Studi Linguistici e Letterari, UniPd
Padova, 13 Febbraio 2024
Luca Giovannini
Università di Potsdam • Università di Padova
Indice
1. Definizione
Digital Humanities
-↳ Digital literary studies
---↳ Computational (literary) criticism
Di cosa parliamo quando parliamo di critica computazionale
Secondo Jannidis 2020 la CLS è un tipo di critica testuale:
- condotta attraverso l'ausilio di strumenti informatici e metodi statistici
- svolta spesso in prospettiva quantitativa (ma attualmente: diffusione dei mixed methods)
- che presuppone modelli di pensiero e di lavoro derivati dalle scienze sperimentali
L'ECOSISTEMA DEI CLS




comprende infrastrutture di coordinamento...
centri di ricerca...
pubblicazioni di settore...
eventi...
Candidatura:
CRITICHE dall'ESterno
(da Jannidis 2020: 10 ff.)
-
Irrilevanza: "lo sapevamo già, non è niente di nuovo"
- Interpretazioni ≠ conoscenza
- "Triangolazione" nel contesto dei mixed methods
-
Inattualità: "usa categorie critiche ormai superate" (come "autore", "genere", "storia letteraria")
- recupero di modelli ancora produttivi/messa in discussione delle impostazioni critiche predominanti
-
Inefficacia: "non riesce a cogliere l'essenza della letteratura"
- ontologicamente diversa, più complessa? (cf. Jannidis 2019)
- approccio descrittivo e non valutativo
- Tappa di riflessione importante: Nan Z. Da, "The Computational Case against Computational Literary Studies" (2019) e dibattito successivo (Critical Inquiry forum)
Moretti, Falso movimento (2023):
- Lo sviluppo accelerato dei metodi statistici ha reciso il legame con la teoria letteraria del Novecento e con il concetto di forma
- Mancanza o rifiuto della teoria, in realtà indispensabile per l'interpretazione del dato scientifico (Kuhn), e prevalenza di approcci esplorativi (EDA)
- tema già dibattuto: vedi ad es. il lavoro della DHd-AG Theorie e di Underwood 2014 (→ gli algoritmi non sono strumenti arbitrari e asettici ma espressione di teorie epistemologiche)
CRITICHE dall'interno
"La statistica è il Pegaso dell’umanista. Spaventosamente cupo, meticoloso e impassibile, è il trampolino di lancio del lirismo, la base da cui il poeta può lanciarsi verso il futuro e le sue incognite, con i piedi solidamente appoggiati su figure, curve, verità umane; in realtà questa lirica potrà interessarci poiché parlerà la nostra lingua, si prenderà cura delle cose che ci riguardano, ci animerà nella direzione del nostro movimento soltanto indicandoci le soluzioni del nostro sistema."
Chi ha paura della statistica?
Le Corbusier, Urbanisme [1925], pp. 99-100

urbanista.
2. metodi
Testo
Formalizzazione
Modellazione

<body>
<div type="act">
<head>Die Erste Abhandelung.</head>
<div type="configuration">
<stage>Der Schauplatz lieget voll Leichen-Bilder / Cronen / Zepter / Schwerdter etc. Vber dem Schau-Platz öffnet sich der Himmel / vnter dem Schau-Platz die Helle. Die Ewigkeit kommet von dem Himmel / vnd bleibet auff dem SchauPlatz stehen.</stage>
<sp who="#ewigkeit">
<speaker>Ewigkeit.</speaker>
<l>Die Ihr auff der kummerreichen Welt</l>
<l>Verschrenckt mit Weh' vnd Ach vnd dürren Todtenbeinen.</l>
<l>Mich sucht wo alles bricht vnd felt /</l>
<l>Wo sich Eu'r ichts / in nichts verkehrt / vnd eure Lust in herbes Weinen!</l>
<l>Ihr Blinden! Ach! wo denckt jhr mich zu finden!</l>
<l>Die jhr vor mich was brechen muß vnd schwinden /</l>
<l>Die jhr vor Warheit nichts als falsche Träum' erwischt!</l>
<l>Vnd bey den Pfützen euch an stat der Quel erfrischt!</l>
<l>Ein Irrlicht ists was Euch O sterbliche! verführet</l>
<l>Ein thöricht Rasen das den Sinn berühret.</l>
<l>Wil jmand Ewig seyn wo man die kurtze Zeit</l>
<pb n="13"/>
<l>Die Handvoll Jahre die der Himmel euch nachsiht</l>
<l>Diß Alter das vergeht in dem es blüht</l>
<l>In Vnmuth theilt vnd in Vergängligkeit?</l>

il processo ermeneutico nei CLS
UN censimento dei metodi per i CLS (link)
-
Testometria (Hyberbase, TXM)
-
Stilometria (Delta & Co.)
-
Estrazione semantica del testo (sentiment analysis, topic modelling, word embeddings)
principali Scuole metodologiche dei CLS

secondo Herrmann et al. 2023
Secondo questa visione, CLS ≈ DLS (stilistica letteraria digitale) (cf. anche Beausang 2020)
- Introdotto da Allison et al. 2015 (= LitLab Pamphlet 1)
- Definizione: "prendere una forma estetica, e smontarla fino a raggiungere i suoi elementi di base: trasformare – anzi, diciamolo, ridurre – un romanzo ai suoi paragrafi, o un dramma a una sequenza di scambi linguistici" (Moretti 2023: 140)
- Investigare la morfologia dell'opera (Propp) attraverso la misurazione di singoli elementi testuali
UN altro approccio:
il formalismo quantitativo
"Operazionalizzare significa costruire un ponte dai concetti alla misurazione e poi al mondo. Nel nostro caso: dai concetti di teoria letteraria, attraverso una qualche forma di quantificazione, ai testi letterari". (Moretti 2013: 1)
un concetto chiave:
L'operazionalizzazione



UN esempio:
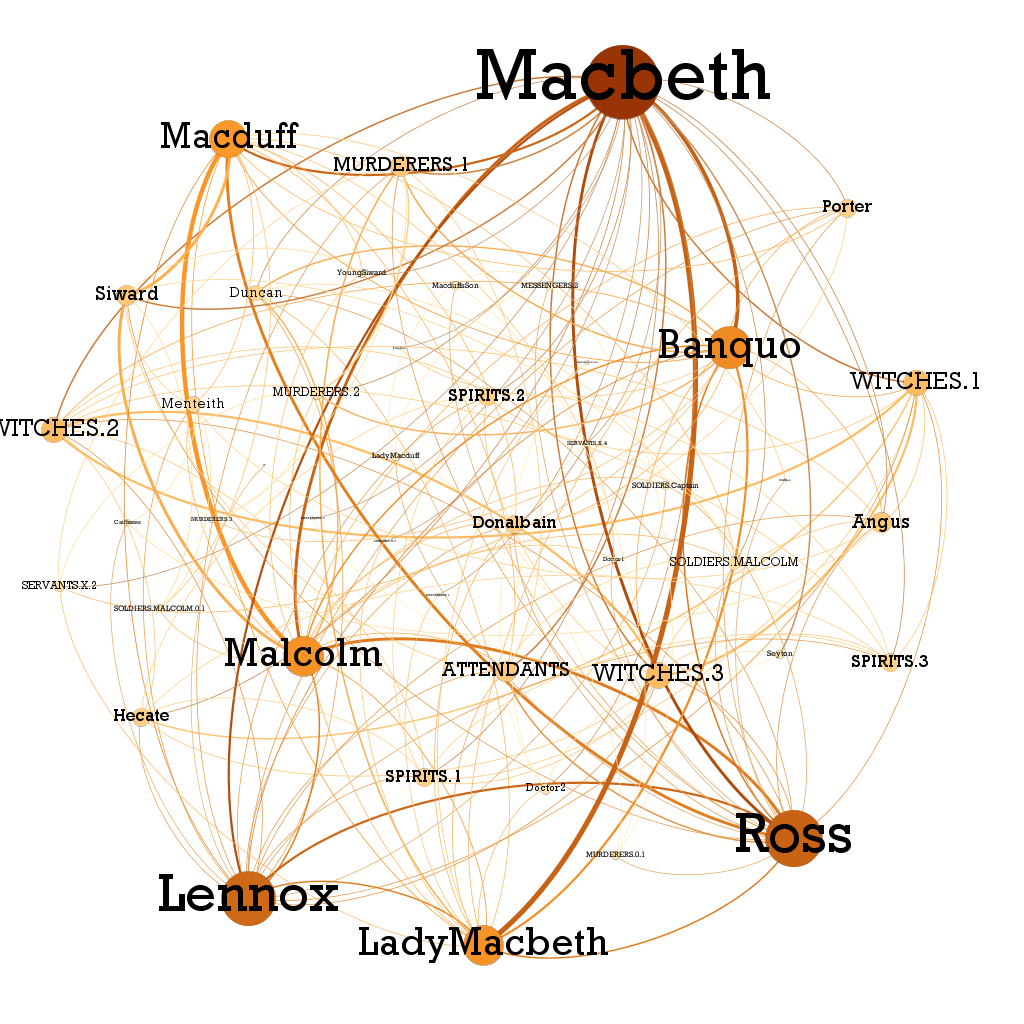
l'ANALISI
DELLE RETI
LETTERARIE
→ Quantificazione di vari tipi di relazioni tra personaggi
→ conversione in grafo
→ analisi con gli strumenti della (social) network analysis
(cf. Trilcke 2013, Algee-Hewitt 2017)
3. prospettive
〞
Lo sviluppo dell’apprendimento automatico (machine learning) rappresenta una risposta significativa
agli argomenti più logori contro i CLS e senza dubbio rivestirà un ruolo significativo nello sviluppo futuro del settore.
Beausang 2020: 195

Dagli anni 2010: sviluppo dell'apprendimento profondo (deep learning), basato su reti neurali complesse
Dagli anni 2020: esplosione dei modelli linguistici di grandi dimensioni (LLM), basati su tecnologia transformer
(es. serie GPT)

-
"un ottimo strumento di supporto per la progettazione e
implementazione di workflow di ricerca" -
"hanno un impatto rilevante nella qualità, [quantità] e efficacia della ricerca umanistica"
Ciotti 2023b: 292
PAPPAGALLI STOCASTICI

| Predizione dell'argomento | Rilevamento della causa di un evento | Analisi di interviste |
| Estrazione di reti di personaggi | Individuazione di passaggi rilevanti | Riuso testuale e concettuale |
| Analisi degli usi linguistici | Misurazione dell'evoluzione semantica lessicale | Annotazione linguistica |
| Rilevamento di opinioni | Individuazione del genere letterario | Analisi comparata di traduzioni |
| Lessicografia | Accrescimento artificiale di dataset | Analisi visuale multimodale |
Un esperimento (Karjus 2023)
Messa alla prova dei LLM con una serie di task:
-
Tutti questi compiti possono essere svolti da un LLM a zero-shot (= senza addestramento specifico) con un risultato qualitativamente simile a quello di un annotatore/esperto umano
-
I modelli sono stocastici e closed-source... proprio come gli esseri umani!
- In prospettiva: delegare alcuni task alle macchine e riservare elaborazioni più complesse (e interessanti) agli umani → verso un "AI-augmented scholar"
- Creazione di figure come il department/lab LLM assistant
RISULTATI E DISCUSSIONE
4. caso studio
Progetto di dottorato: Quantitative Approaches to European Early Modern Drama (2021-)
1. Un problema di Storia letteraria:
l'evoluzione del teatro europeo nella prima modernità
Secondo Moretti (1993) il meccanismo evolutivo della storia letteraria è simile a quello nella biologia: come nuove specie nascono in conseguenza del movimento in nuovi spazi ...
... così nuove forme letterarie nascono grazie ai nuovi spazi politico-geografici che si creano nella storia (europea)

la speciazione delle forme letterarie
La varietà morfologica del teatro europeo si spiega in ragione della geografia politica del continente:
"Lo spazio europeo va insomma concepito come una sorta di arcipelago: un insieme di spazi (nazionali) ognuno dei quali produce una (e una sola) mutazione formale."
(Moretti 1993: 10-11)
1400 1500 1600 1700 1800
Modello "uniforme" del dramma europeo
(influenzato da Seneca e dalle tradizioni medievali)
Varianti nazionali
come misurare empiricamente questo processo di diversificazione?
🇫🇷
🇩🇪
🇮🇹
🇬🇧
🇪🇸
2. corpus
-
150 testi teatrali in cinque lingue (🇮🇹 🇫🇷 🇪🇸 🇩🇪 🇬🇧)
-
arco cronologico: 1561-1710 (150 anni)
-
approccio deliberatamente non canonico
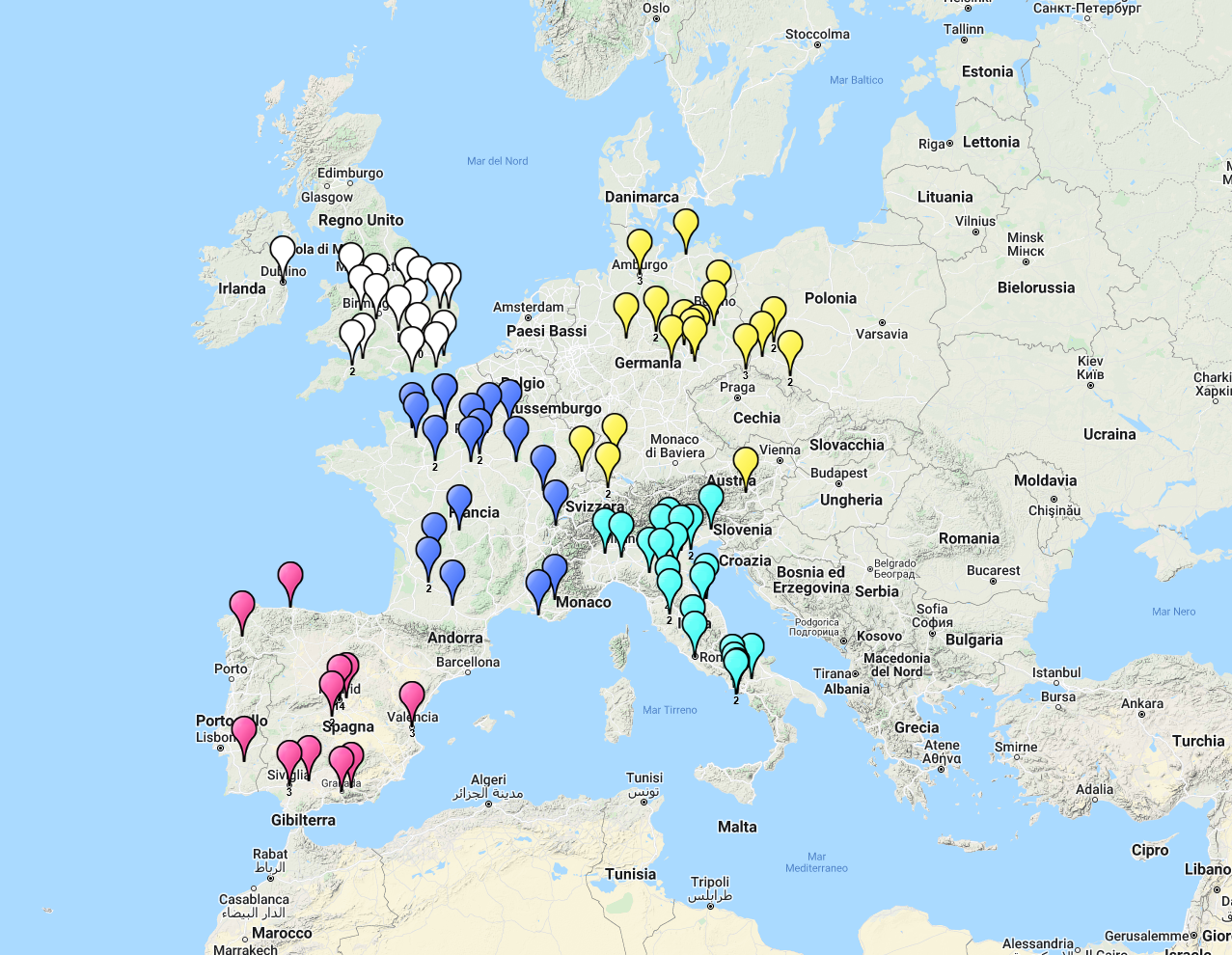
Luoghi di nascita degli autori (via Wikidata, dati incompleti)
OBBIETTIVo: integrazione in dracor
- DraCor (Drama Corpora) è una piattaforma open-access per la ricerca sul teatro europeo (Fischer et al. 2019, https://dracor.org)
-
Ospita +3000 testi (TEI-XML) in 10 lingue con varie applicazioni per la critica computazionale

- Grazie a Docker è possibile creare corpus personalizzati da file locali e indagarli con tutti gli strumenti di DraCor
-
Creazione di EmDraCor:
- dracorizzazione di file XML esistenti
- codifica (non filologica) di nuove opere solo dove necessario + dracorizzazione

3. METODOLOGIA:
un approccio globale alla forma drammatica
- Nella tradizione dei formalisti russi (Boris Yarkho), di Solomon Marcus e dei moderni formalisti quantitativi
- Cercare di operazionalizzare più componenti del dramma possibili (es. dialoghi, personaggi, trama) per ottenere un profilo quantitativo dell'opera


VETTORIZZAZIONE: concepire l'opera come una collezione di meta-DAti
- Estrazione di un ampio range di statistiche testuali (su personaggi, intreccio, struttura, dialoghi, etc.) tramite l'API di DraCor e script specifici
- Uso delle statistiche per rappresentare i testi sotto forma di vettori (play embeddings), i quali permettono di misurare alcune proprietà dei drammi e le loro relazioni
numero di personaggi: 13
densità della rete: 0.9
conteggio dialoghi: 23453
conteggio didascalie: 3456
....
vettore dell'opera =
(13, 0.9, 23453, 3456, ....)
Un possibile approccio di ricerca: rappresentare
i drammi-vettori come punti in un sistema di coordinate
(tramite metodi di riduzione della dimensionalità, es. PCA)
Dramma_8
Dramma_5
Dramma_4
Dramma_3
Dramma_2
Dramma_1
Dramma_7
Dramma_6
In questo modo, è possibile calcolare le distanze tra testi e individuare cluster basati su somiglianze strutturali
Se la teoria di una progressiva differenziazione formale del dramma su base nazionale è corretta,
la rappresentazione grafica dei vettori delle opere dovrebbe mostrare un'andamento simile:
1561 (somiglianza) 1710 (differenziazione)
🇫🇷
🇩🇪
🇬🇧
🇮🇹
🇪🇸
- Si è riscontrato in effetti un aumento della diversità formale (anche all'interno di singoli generi)...
- ... ma non una compartimentazione così netta su base nazionale (cf. teorie concorrenti di Küpper/Clubb)
- È possibile comunque delineare profili quantitativi delle letterature teatrali nazionali basati su alcuni elementi distintivi (work-in-progress)
- Valore del lavoro oltre al tema di ricerca specifico:
- proporre la vettorizzazione come metodo efficace per lo studio formale della letteratura in una prospettiva affine alle cultural analytics
RIsultati PROVVISORI
-
Allison, S.; Heuser, R.; Jockers, M.; Moretti, F.; Witmore, M. (2011). "Quantitative Formalism: An Experiment". Stanford Literary Lab Pamphlet 1.
-
Beausang, C. (2020). "A Brief History of the Theory and Practice of Computational Literary Criticism (1963-2020)". magazén 1, 2, pp. 181-202.
-
Ciotti, F. (2023). "L'analisi del testo". In: Ciotti, F. (ed.), Digital Humanities – Metodi, strumenti, saperi. Roma: Carocci, 2023.
-
Ciotti, F. (2023b). "Minerva e il pappagallo: IA generativa e modelli linguistici nel laboratorio dell’umanista digitale". Testo e Senso 26, pp. 289-315.
-
Da, N. Z. (2019). "The Computational Case against Computational Literary Studies". Critical Inquiry, 45, 3, pp. 601–39.
-
Fischer, F., Börner, I.; Göbel, M.; Hechtl, A.; Kittel, C.; Milling, C., Trilcke, P. (2019). "Programmable Corpora: Introducing DraCor, an Infrastructure for the Research on European Drama". In: DH2019 Book of Abstracts. Università di Utrecht, 2019.
-
Jannidis, F. (2019). "On the Perceived Complexity of Literature. A Response to Nan Z. Da". Journal of Cultural Analytics 5, 1.
riferimenti bibliografici
-
Jannidis, F. (2022). "Digitale Literaturwissenschaft. Zur Einführung". In: Jannidis, F. (ed.), Digitale Literaturwissenschaft. Stoccarda: J. B. Metzler, pp. 1-16.
-
Herrmann, J. B.; Bories, A.-S.; Frontini, F.; Jacquot, C.; Pielström, S.; Rebora, S.; Rockwell, G.; Sinclair, S. (2023). "Tool Criticism in Practice: On Methods, Tools, and Aims of Computational Literary Studies". Digital Humanities Quarterly 17, 2.
-
Moretti, F. (1993). "La letteratura europea", in P. Anderson, W. Barberis, e C. Ginzburg (ed.), Storia d'Europa, vol. I (L’Europa Oggi). Torino: Einaudi, pp. 837–66.
-
Moretti, F. Distant reading. Londra: Verso, 2009.
-
Moretti, F. (2013). " 'Operationalizing': or, the function of measurement in modern literary theory". Stanford Literary Lab Pamphlet 6.
-
Moretti, F. (2023). Falso movimento: la svolta quantitativa nello studio della letteratura. Milano: Nottetempo.
-
Schöch, C.: Dudar, J.; Fileva, E., eds. (2023). Survey of Methods in Computational Literary Studies, v1.1.0, Trier: CLS INFRA.
-
Underwood, T. (2014). "Theorizing Research Practices We Forgot to Theorize Twenty Years Ago". Representations 127, 1, pp. 64–72.
riferimenti bibliografici
📧 giovannini@uni-potsdam.de
📧 luca.giovannini@unipd.it
