Computational approaches to opera libretti

2nd Conference for Computational Literary Studies, Würzburg, 23.06.2023

Luca Giovannini — Daniil Skorinkin
University of Potsdam, Germany
Summary
-
Research question
-
Corpus
-
Experiments
-
Findings and discussion
This presentation: plu.sh/libretti
1. Research question
Libretto
-
Working definition: modern dramatic texts where music plays a central role
-
Born in the early 17th century in Italy and rapidly exported across Europe
-
Traditional scholarship focused more on music than on words
-
Even librettology is still largely non-computational

Some questions
-
Is it possible to consider libretti a unitary genre with its own structural features?
-
Do libretti possess a peculiar "genre signal" which sets them apart from contemporary comedies and tragedies?
-
How did the structure of libretti evolve compared to the other genres?
2. Corpus
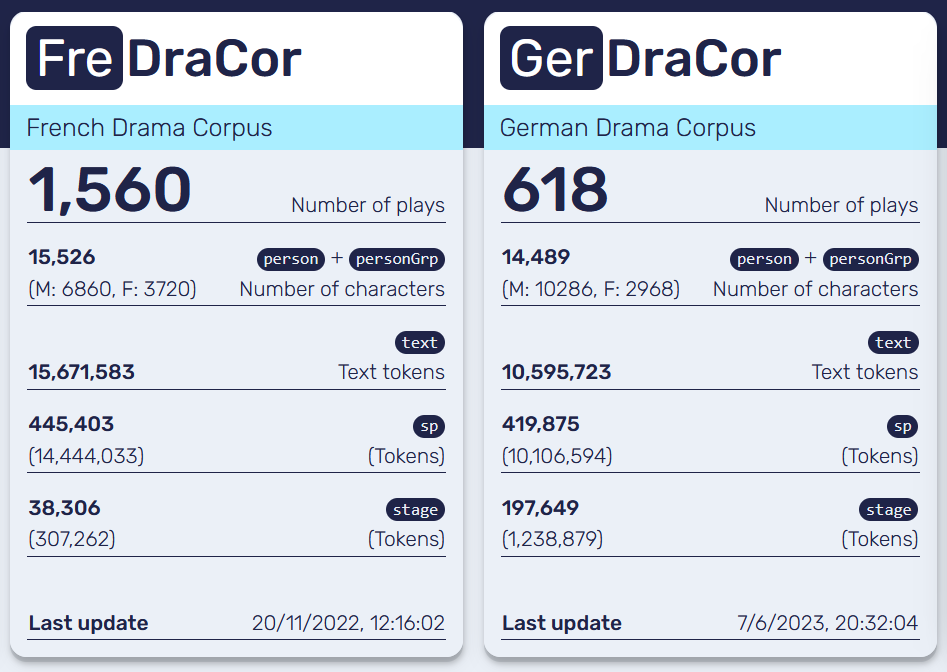
Starting point: DraCor corpora
(☞ Fischer et al. 2017, dracor.org)
Initial survey and preprocessing
- Check how many texts in our corpora were marked as
libretto(55 🇩🇪 /58 🇫🇷) - Disambiguate 🇫🇷 multi-label (= libretto and something else) plays → keeping only
librettoas tag - Our initial hypothesis: the intended usage of a libretto is more distinctive than its generic alignment
Corpus enrichment
- Retrieve all items with the
'subtitle'containing one of these labels for operatic subgenres (e.g. drame lyrique, opéra-ballet, Singspiel, Spieloper) - Qualitative check, then append to 'libretti' list
DraCor plays without genre tags?
Libretti not identified as such?
- Retrieve Wikidata genres through the plays' Wikidata IDs (in the TEI markup)
- Map genres manually to one of 5 categories (Comedy, Tragedy, Tragicomedy, Libretto, None)
- Update metadata
Enrichment results

🇩🇪
+ 51%
🇫🇷
+ 55%
3. Experiments
Exploratory data analysis as a methodological choice
- No strong hypothesis on how the structure of a libretto would have looked like
- "Let data speak by themselves"

A quite simple pipeline
Vectorisation of plays according to structural features
(cf. Szemes and Vida 2022)
EDA on different textual aspects
Vectorisation
- Get almost all numeric features from the metadata tables (via DraCor API)
- Create vectors for each play
num_of_segments, num_of_speakers,
num_of_person_groups, word_count_sp,
word_count_stage, average_degree, density,
average_clustering, max_degree,
num_of_connected_components,
diameter, average_path_length
A combination of network measures and size statistics
Experiment #1
Naïve visualisation
Procedure
- Split the corpora into roughly 50-year spans to follow closely the genre's evolution
- Apply dimensionality reduction methods (PCA) to the vectorised plays and plot them
-
Results were unsatisfying: no meaningful clustering, no signs of libretto being a unitary genre
Semi-automatic labelling of libretti as comic/non-comic, based on their subtitles (e.g. komische Oper → comic libretto)
Refining our operationalisation
Results: clustering still messy BUT
significant topological patterns emerge
One interesting example:
the 🇫🇷 1670-1719 timeframe

comic space
tragic zone
non-comic libretti
Experiment #2
Finding relevant features
measuring statistical significance of feature variation
- Shapiro-Wilk test
- Wilcoxon Rank-Sum test
training a Random Forest Classifier
- 5-fold cross validation on all data
- Iterative selection of the best n estimators parameter (10-1000)
- Removed highly correlated values
Pipeline
single out the most significant features for further inspection
Most discriminative features for libretti
word_count_stageword_count_spnum_connected_componentsdensitynum_of_speakersdiameter
word_count_spnum_of_person_groupsaverage_degree
Experiment #3
Plotting the evolution
of interesting features
Charting the most interpretable features as scatterplots
-
four-class implementation
-
plotting each play individually
-
LOWESS-based smoothing curves to make trends visible
4. Findings and discussion

1. Libretti as a whole show some distinctive traits
Libretti have consistently less spoken text (above) and more stage directions (below)
2. Non-comic libretti often follow an independent path


🇩🇪 num_of_person_groups / word_count_sp
🇫🇷 density / num_speakers
3. The French dramatic space is more formalised than the German one
- Looking at PCA clusterings, it seems slightly easier to discriminate between different genres in 🇫🇷
- Historical reasons:

The two types of French libretti (blue) are structurally more distinct than the German ones (orange)
Limitations
- Corpora extension and markup quality
- Comparative approach: lack of 🇮🇹
- Difficulties in modelling relations between dramatic texts on the basis of formal features
- Could we do better?
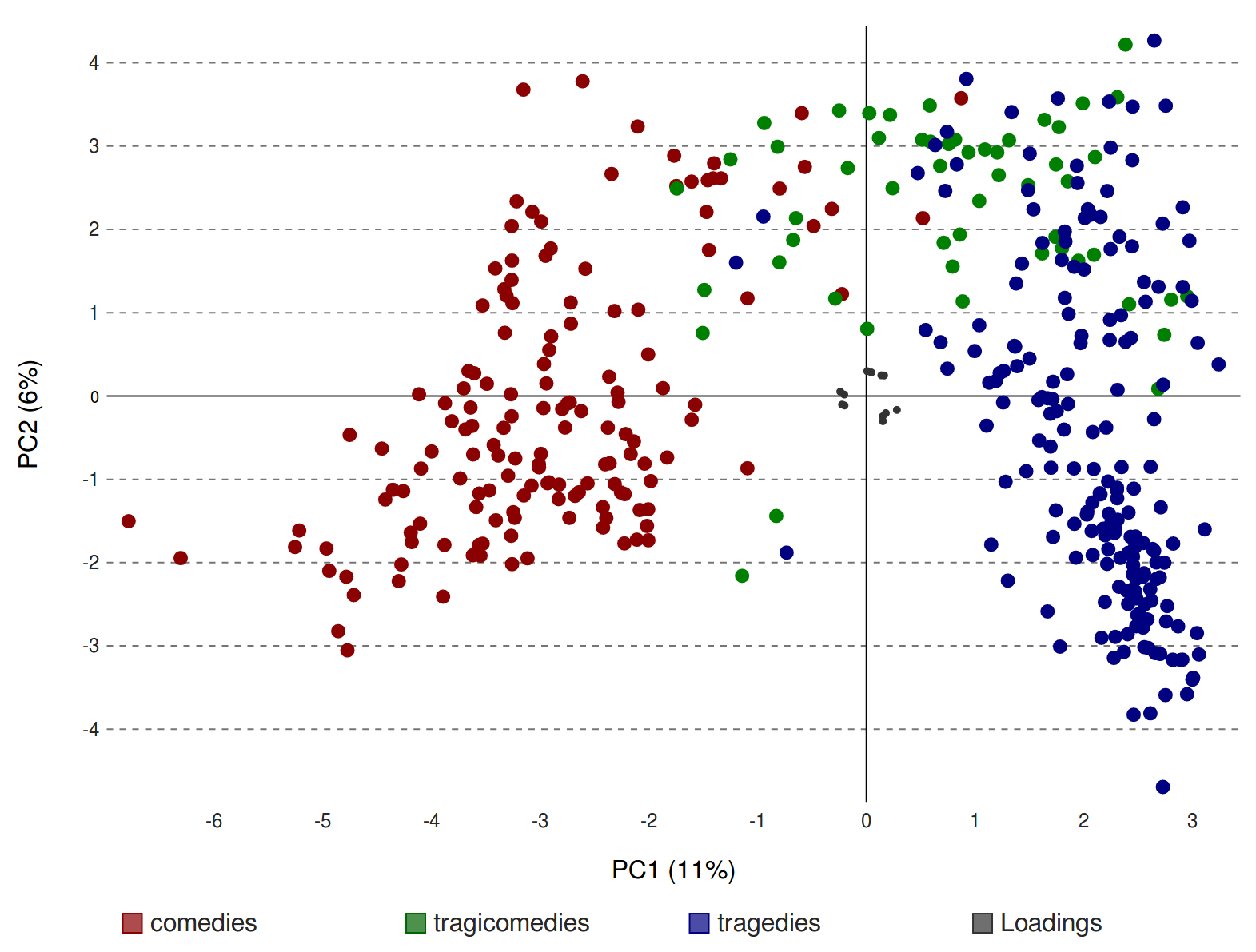
Comparison: topic modelling (Schöch 2017)
-
Individual structural features might be useful for distinguishing one (sub-)genre from the other
-
However, it is generally not easy to distinguish between plays formalised as vectors of multiple features
-
Drama often seems too homogenous, in terms of structural properties, for discriminative clustering
-
Need to find better features (or construct better measures) // rethink operationalisation patterns
In lieu of a conclusion
Thanks for listening!
Questions?